

 CX & Survey Software
CX & Survey Software Offline & Kiosk Survey
Offline & Kiosk Survey Product Feedback
Product Feedback Customer Service Feedback
Customer Service Feedback Surveys for Salesforce
Surveys for Salesforce Website Feedback
Website Feedback%201.svg) Email Surveys
Email Surveys%201.svg) SMS Surveys
SMS Surveys WhatsApp Surveys
WhatsApp Surveys%201.svg) In-App Feedback
In-App Feedback%201%20(1).svg) In-Product Feedback
In-Product Feedback%201.svg) Offline Surveys
Offline Surveys.svg) In-App Mobile SDK
In-App Mobile SDK Survey Builder
Survey Builder 30+ Question Types
30+ Question Types Pre-built Templates
Pre-built Templates Skip Logic
Skip Logic White-Labeling
White-Labeling Multilingual Surveys
Multilingual Surveys Pre-filled Survey Data
Pre-filled Survey Data Microsurveys
Microsurveys Feedback Button
Feedback Button Digital Feedback
Digital Feedback Recurring Surveys
Recurring Surveys Survey Throttling
Survey Throttling Integrations
Integrations APIs & Webhooks
APIs & Webhooks CX Automation
CX Automation Closing Feedback Loop
Closing Feedback Loop Response Inbox
Response Inbox Real-time Alerts
Real-time Alerts  Location-Based CX
Location-Based CX  Agent-Based CX
Agent-Based CX  Survey Reports
Survey Reports Comparative Reports
Comparative Reports CSAT Metrics
CSAT Metrics Text Analysis
Text Analysis.svg) Help Center
Help Center%201%20(1).svg) Developer Center
Developer Center Customer Stories
Customer Stories.svg) Blogs and Insights
Blogs and Insights.svg) Guides
Guides Salesforce
Salesforce  HubSpot
HubSpot ActiveCampaign
ActiveCampaign Pipedrive
Pipedrive Mailchimp
Mailchimp Zendesk
Zendesk  Freshdesk
Freshdesk HelpScout
HelpScout  Front
Front Slack
Slack  Webex
Webex Zoom
Zoom Google Sheets
Google Sheets  Zapier
Zapier  Integrately
Integrately Webhooks
Webhooks  Developer APIs
Developer APIs

Analyzing sentiments using models trained on labeled feedback data such as CES, CSAT, and Net Promoter Score is a well-known practice in sentiment analysis. However, the real challenge emerges when dealing with unstructured or unlabeled data from open-ended comments.
And with over 80% of the CX data within enterprises being unstructured, the challenge cannot be overlooked.
This is where unsupervised sentiment analysis comes in.
With unsupervised learning models for sentiment analysis, enterprises can get a nuanced view of customer attitudes, sentiments, behavior trends, and even operational bottlenecks from all kinds of customer data and not just one with labels, formats, and structure.
The Machine Learning and Natural Language Processing algorithms trained on unstructured data can extract crucial insights that are otherwise hard to identify within text comments, reviews, feedback, and more.
Understanding Unsupervised Sentiment Analysis
To understand unsupervised sentiment analysis, we’d have to first get acquainted with the technique- sentiment analysis.
In order to grasp the concept of unsupervised sentiment analysis, it is essential to familiarize ourselves with the technique known as sentiment analysis.
Often termed opinion mining, sentiment analysis is the process of analyzing text to determine the sentiment or emotional tone expressed within. The main objective of sentiment analysis is to automatically classify text as positive, negative, or neutral based on the emotions conveyed by the words.
It gives businesses the power to extract valuable insights from large volumes of text data.
This text data can be broadly categorized into two parts: structured or unstructured data, depending on the sources, formats, and, of course, the structure.
Responses to questions with scales, buttons, choices, etc., such as CSAT, NPS, or CES, are categorized as structured data. At the same time, any type of feedback received on open comment boxes is unstructured.
What unsupervised analysis does is it breaks down the unsupervised text data to extract meaningful insights and action plans.
For instance, feedback received on a luxury jewelry site wouldn't highlight all the sentiments hidden in the customer's response if it wasn't for an open-ended question.
Unsupervised sentiment analysis helped identify the sentiments, emotions, intent, and a lot of other aspects of the feedback that would've gone unnoticed otherwise.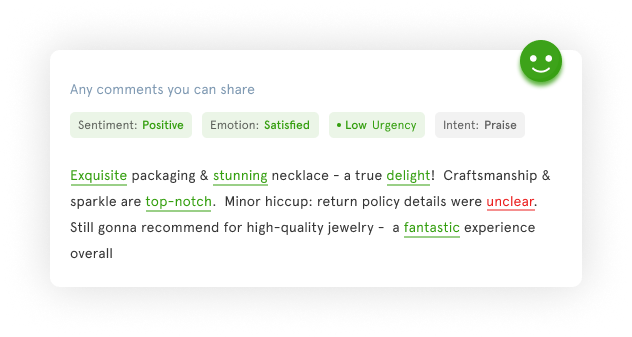
Unstructured data refers to data that does not have a predefined format or organization, such as text documents, social media posts, customer reviews, emails, and more.
For example, a comment like "The service was great. We would love to visit again" shows a positive sentiment. At the same time, something like "The interface was cluttered and I was unable to complete the transaction" denotes a negative sentiment.
In unsupervised sentiment analysis, the models do not rely on labeled data with predefined sentiment labels (positive sentiment, negative sentiment, neutral). Instead, they analyze the inherent structures, patterns, and semantics within the text to infer sentiment without explicit supervision. This approach allows unsupervised analysis of sentiments to handle unstructured text data without requiring prior annotations or labeling of sentiment.
💡What is Unsupervised Sentiment Analysis?
Unsupervised sentiment analysis is a technique used to understand the overall feeling or opinion expressed within a text, without requiring any pre-labeled data for training. This is in contrast to supervised sentiment analysis, which relies on pre-labeled examples (e.g., rating scale questions, multiple choices, Likert scale, and similar scales) to train a model.
Unsupervised methods may utilize techniques such as natural language processing (NLP), machine learning algorithms, lexicon-based approaches, clustering, topic modeling, or rule-based methods to uncover sentiment patterns and classify text into sentiment categories. These techniques enable unsupervised sentiment analysis to extract valuable insights from unstructured textual data, making it a valuable tool for various applications in sentiment analysis, opinion mining, and text analytics.
Understanding the Difference: Supervised Vs. Unsupervised Sentiment Analysis
Businesses usually take two approaches to sentiment analysis- supervised and unsupervised. Any algorithm can be taught with both these approaches to distinguish between negative and positive emotions.
Unlike supervised methods that require pre-labeled data, unsupervised approaches analyze text without needing pre-categorized examples. This makes them ideal for situations where labeled data is scarce or unavailable, such as when dealing with a new product or service.
Supervised Sentiment Analysis
In supervised learning, sentiment analysis models are trained on labeled datasets where each text sample is associated with a sentiment label (e.g., positive, negative, neutral). These models learn to classify new text based on patterns and features extracted from the training data. Supervised methods require a large amount of labeled data for training and are effective when accurate annotations are available.
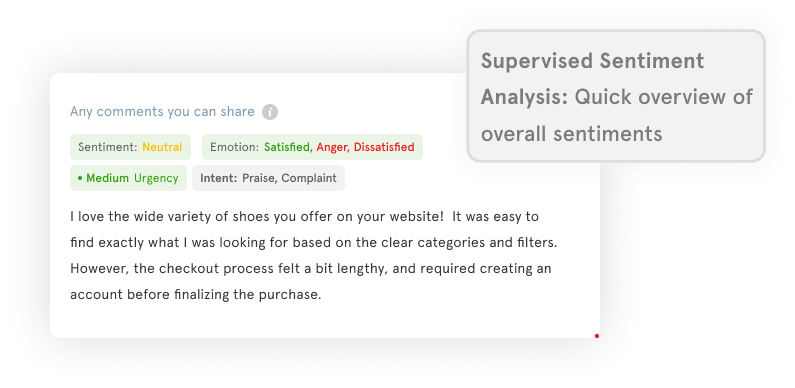
However, they may struggle with domain-specific or evolving sentiments.
Unsupervised Sentiment Analysis
Unsupervised learning involves analyzing data without labeled examples. In unsupervised sentiment analysis, the models identify patterns, clusters, or semantic structures within the text to infer sentiment without relying on labeled data. This approach is valuable in scenarios where labeled data is scarce or expensive to obtain.
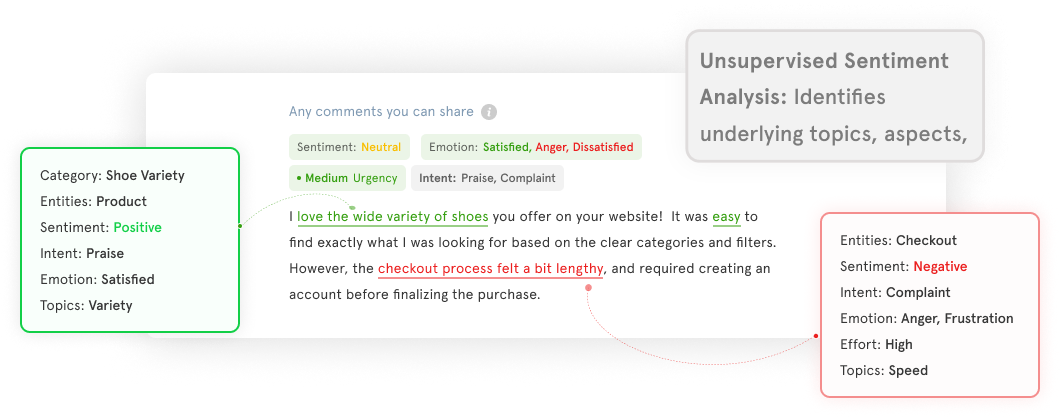
Unsupervised methods can discover hidden sentiment patterns and adapt to diverse domains or languages.
| Aspect |
Supervised Sentiment Analysis |
Unsupervised Sentiment Analysis |
|
Training Data |
Requires labeled data with sentiment annotations. |
Does not require labeled data; and analyzes unlabeled text. |
|
Approach |
Learns from labeled examples to classify new text. |
Analyzes inherent patterns and structures in the text. |
|
Training Process |
Supervised learning algorithms are used for training. |
Various techniques like clustering, topic modeling, etc. |
|
Annotation Effort |
High annotation effort to create labeled datasets. |
No need for annotation; works with unlabeled data. |
|
Scalability |
May require continuous updates with new labeled data. |
More scalable for analyzing large volumes of text. |
|
Flexibility |
May struggle with domain-specific or evolving sentiments. |
Can adapt to different domains and languages. |
|
Cost |
Can be expensive due to the need for labeled data. |
More cost-effective as it doesn't require labeling. |
|
Performance |
Typically achieves higher accuracy with labeled data. |
Performance may vary based on data quality and techniques. |
|
Use Cases |
Commonly used in applications with access to labeled data. |
Suitable for scenarios where labeled data is scarce. |
|
Examples |
Support vector machines, Naive Bayes, neural networks. |
Clustering, topic modeling, lexicon-based approaches. |
Approaches for Unsupervised Sentiment Analysis
By now we know that unsupervised sentiment analysis analyzes text data that does not have any pre-labeled sentiment annotations. So how do these algorithms analyze text data that do not have any labels?
There are different approaches that these analysis models follow:
#1. Lexicon-based
Used in Natural Language Processing, lexicon-based sentiment analysis enables businesses to extract sentiments from text data. It uses lexicons or dictionaries or a valence aware dictionary that comprises a list of phrases or words with annotated sentiment polarities like positive, negative, or neutral.
By matching words in the text with entries in the lexicon, sentiment orientations can be inferred. One can also use the lexicon-based approach to perform sentiment analysis. It assigns sentiment scores based on their polarity. These sentiment scores can then be evaluated to give an overview of the sentiment expressed in the unstructured text data.
#2. Clustering
Clustering is an approach that specializes in grouping similar data points or documents based on specific criteria. It works best in unsupervised sentiment analysis for categorizing text data. It can group them based on their semantic content, connectivity, word usage pattern, etc.
This helps create subsets of data from the unlabeled sets and organize them into nested clusters. You can choose from different clustering algorithms like k-means, hierarchical, or spectral clustering to create clusters. The predominant sentiment in each cluster can help analyze your complete data set.
Using clustering, you can detect anomalies, outliers, overall sentiment, or even any rare sentiment within your data without predefined labels or categories.
#3. Topic Modeling
Topic modeling, one of the most popular Machine Learning techniques, is another popular unsupervised approach to sentiment analysis. It works by scanning through large collections of text data or documents and discovering abstract topics within each. It uses text mining techniques to detect the frequency of usage of certain words or phrases and groups them under topics that best represent their information.
By ‘topic’ we mean a collection of words with similar associations. For instance, words like features, functionality, software, interface, user-friendly, customizable, interface, etc., would fall under the topic ‘user experience’ or ‘features and functionality’ based on the text data you’re working with.
Now there are two approaches to topic modeling as well- Latent Dirichlet Allocation (LDA) and Latent Semantic Analysis (LSA). LDA categorizes data into topics based on the arrangement of words or the distributional hypothesis. LSA, on the other hand, works on the context of the words. This means the semantics of the words would be similar if they have similar contexts.
Other Approaches to Unsupervised Sentiment Analysis
These were the three most popularly used unsupervised approaches for analyzing sentiments from text data or documents. However, there are various other approaches that businesses adopt to extract sentiments from their data like text feedback from survey responses, social media, emails, etc.
Here are some of those:
- Rule-Based Approach: Define rules or heuristics based on linguistic patterns, syntactic structures, or sentiment indicators to identify sentiment cues within the text data. For example, identifying negations, intensifiers, emoticons, or sentiment-bearing phrases.
- Graph-Based Methods: Construct semantic graphs where nodes represent words or phrases, and edges represent semantic relationships (e.g., co-occurrence, similarity). Analyzing the graph structure can reveal sentiment associations and patterns.
- Word2Vec: Represent words in a continuous vector space where semantically similar words are located close to each other. Analyzing the distributional properties of words can reveal sentiment patterns and associations.
Why Use Unsupervised Sentiment Analysis?
Not every text data, whether received from feedback, survey responses, emails, chat/call logs, etc., is going to have labels assigned to it. In fact, the majority of the data out there is unstructured, unlabeled, and without any classification.
So, it goes without saying that the importance of performing sentiment analysis using the unsupervised approach is quite prominent in the data ecosystem.
In the context of customer feedback analysis, unsupervised sentiment analysis offers several advantages that make it particularly suitable for extracting insights from unstructured text data. Here are the advantages:
- Scalability: Customer feedback often comes in large volumes from various channels such as social media, online reviews, feedback surveys, and customer support interactions. Unsupervised sentiment analysis can efficiently process and analyze this vast amount of unstructured text data without the need for manual annotation, making it highly scalable for handling large-scale customer feedback datasets.
- Real-time Analysis: Customer feedback is often time-sensitive, requiring timely responses to address customer concerns and issues. It can provide real-time analysis of customer feedback, enabling businesses to quickly identify emerging trends, sentiments, and issues as they arise and take prompt action to address them.
- Exploratory Analysis: Customer feedback data can be rich and diverse, containing various topics, opinions, and sentiments expressed by customers. Unsupervised sentiment analysis allows for exploratory analysis of customer feedback, uncovering hidden sentiment patterns, topics of interest, and customer preferences without prior assumptions or bias, leading to new insights and opportunities for improvement.
- Cost-effectiveness: Manual annotation of customer feedback data for sentiment analysis can be time-consuming and expensive. Unsupervised analysis of sentiments eliminates the need for manual labeling, reducing the overall cost associated with analyzing customer feedback data. This cost-effectiveness makes it feasible for businesses of all sizes to leverage sentiment analysis to gain insights from customer feedback.
- Adaptability to Multilingual Data: In today's global marketplace, businesses often receive customer feedback in multiple languages. With this technique of unsupervised analysis, you can analyze multilingual data without the need for language-specific models or labeled datasets, making it adaptable to diverse language settings and enabling businesses to gain insights from customer feedback across different markets and regions.
- Identifying Emerging Issues: Customer feedback can uncover emerging issues, trends, or patterns that may not be apparent through traditional methods. With the technique of unsupervised analysis of sentiments, one can detect subtle changes in sentiment and identify emerging issues or concerns expressed by customers, allowing businesses to proactively address these issues before they escalate or impact customer satisfaction.
Getting Started with Unsupervised Sentiment Analysis
Unsupervised sentiment analysis acts as a valuable tool for businesses to gain insights from customer surveys. While it may not replace human understanding, it can provide a starting point for further investigation and inform strategic decision-making.
With so much unstructured data coming in from open-ended customer feedback, reviews, social media comments, and other data points and sources, businesses are fast adopting the unsupervised approach to perform sentiment analysis.
With Zonka Feedback, you get an all-in-one customer experience software that not only helps you collect feedback through open-ended questions across multiple touchpoints but also analyzes the text data to determine positive sentiments, negative sentiments, or neutral feedback. It has a powerful sentiment analysis tool as well as a text analytics tool that analyzes complete text data, whether structured or unstructured, and offers positive scores, negative scores, or other related sentiment scores.
In addition to extracting sentiment value from feedback, it also performs intent analysis, emotion detection, opinion mining, text mining, and much more.
You can sign up with Zonka Feedback to enjoy a free 14-day trial or schedule a demo with the team to understand the tool better.














